Reflections on the DCMI Abstract Model (2011)
Note: This short piece, posted to a DCMI wiki in 2011, was reformatted and lightly edited for the DCMI blog in 2019.
The DCMI Abstract Model (DCAM) specifies an abstract syntax for metadata records independent of particular concrete encoding syntaxes. The components of DCAM's abstract syntax map unambiguously to components of the RDF abstract syntax. In addition, DCAM's abstract syntax provides several grouping constructs not present in RDF -- notably "description sets" (mappable in principle to a named graph instantiated as a "metadata record"), "descriptions" (mappable in principle to a sub-graph of RDF triples about a single subject), "DCAM statements" (mappable to a sub-graph composed of an RDF statement plus contextual information about the value of that statement), and "value surrogates" (mappable to the different sets of statements used to describe values directly encoded as literal string values as opposed to values identified by URIs or blank nodes).
These constructs are used to group syntactic "slots" for holding the URIs and string literals used in instance metadata. URIs (for identifying described resources, values, properties, vocabulary encoding schemes, or RDF datatypes) and literals (language tags or text strings) are the components of the DCAM abstract syntax that can be tested or validated. The DCMI Abstract Model was designed to be used together with a constraint language for specifying the contents of application-specific metadata record formats in a form independent of particular concrete encoding syntaxes -- the function of a Dublin Core™ application profile.
Early efforts to define a data model for Dublin Core™
The Dublin Core™ community began in 1995 by defining twelve (later fifteen) elements. These elements were supplemented in 1997 by the addition of qualifiers (originally called Canberra qualifiers. In July 2000, with the publication of a DCMI Recommendation, Dublin Core™ Qualifiers, qualifiers were differentiated into "element refinements" and "element encoding schemes". This typology evolved into a 2003 guide for DCMI Usage Board vocabulary maintenance decisions - DCMI Grammatical Principles - which further divided "encoding schemes" into "vocabulary encoding schemes" and "syntax encoding schemes".
In addition to the development of a "typology of terms", and specific sets of terms based on that typology, an effort was made to specify a format-independent abstract data structure - an "abstract syntax" within which references to those terms were made. This work was summarized in a 2000 D-Lib Magazine article, A Grammar of Dublin Core, which articulated a "grammar" of "statements" comprised of several components:
- an implicit reference to a thing being described
- a reference to one of the fifteen "properties" or "elements" of the Dublin Core™ Metadata Element Set
- a "property value" (characterized as "an appropriate literal")
- optional references to one or more "qualifiers"
The first specification for a concrete syntax for Dublin Core™ metadata, RFC 2731: Encoding Dublin Core™ Metadata in HTML, was based at least informally on this model.
Starting in 1997, the development of a metadata model in DCMI paralleled W3C's push to define a generic Resource Description Framework (RDF)--an effort that culminated in a first W3C Recommendation, RDF Model and Syntax Specification of February 1999 and, following an extensive review process, a second W3C Recommendation RDF Concepts and Syntax in February 2004. Following up on the standardization of RDF, DCMI developed "encoding guidelines" specifying two slightly different conventions for using Dublin Core™ terms with RDF:
- Expressing Simple Dublin Core™ in RDF/XML of 2002, which specified the use of Dublin Core™ properties exclusively with literal values.
- Expressing Qualified Dublin Core™ in RDF of 2002, which specified the use of object values and of Bag, Seq, and Alt constructs and discussed the use of subproperty relations for the principled simplification ("dumb-down") of complex descriptions.
The rationale for the DCMI Abstract Model
By the early 2000s there was a growing number of "Dublin Core™ metadata" implementations, most of which lacked any sort of reference to a common abstract syntax. The result was a landscape of applications among which interoperability was problematic. The RDF abstract syntax was recognized by parts of the Dublin Core™ community as an enabling technology for interoperability -- and the "grammar of Dublin Core™" model was intended in part to popularize its notion of "statement-based" metadata -- but RDF was seen by a large part of the Dublin Core™ community as a research project of dubious practical value. RDF was seen less as a fundamentally different way of conceptualizing metadata and more as an alternative XML format for metadata -- and one that compared unfavorably to apparently simpler and more readable XML formats.
Given the difficulty of directly promoting the RDF abstract syntax as a common basis for metadata, work began in 2003 on a DCMI Abstract Model in an attempt:
- to clarify and formalize the "home-grown" model of metadata that had emerged from early Dublin Core™ workshops and formed the basis of the DCMI Grammatical Principles; and
- increasingly, over time, to align that model with that of the RDF abstract syntax and RDF semantics.
This effort resulted in a first DCMI Abstract Model as a DCMI Recommendation in March 2005 and a second, revised model in June 2007. The 2007 revision moved closer to RDF terminology by de-emphasizing the word "element" in favor of "RDF property", explicitly defining "element refinements" as "RDF sub-properties" and Syntax Encoding Schemes as RDF datatypes, and further de-emphasizing the generic designations "encoding scheme" and the even more generic term "qualifier".
The DCMI Abstract Model defined an abstract syntax based on a data structure it called the Description Set. The specification Expressing Dublin Core™ metadata using the Resource Description Framework (RDF) of 2008 explained how the description set model mapped to the abstract syntax of RDF. The revised DCMI Abstract Model of 2007 became the basis for the revised concrete syntax specifications Expressing Dublin Core™ metadata using HTML/XHTML meta and link elements (aka DC-HTML), Expressing Dublin Core™ Description Sets using XML (DC-DS-XML), and Expressing Dublin Core™ metadata using the DC-Text format.
In 2009, Mikael Nilsson outlined a potential RDF-based version of the DCMI Abstract Model as a dramatic simplification of the 2007 model. The proposed revision would have dropped two of the three component models of the 2007 model: the DCMI Resource Model (to be replaced by a simple reference to RDF) and the DCMI Vocabulary Model (to be replaced by a simple reference to the RDF Vocabulary Description Language, also known as RDF Schema). The motivation for this proposed revision, never developed into a full specification, was to define the abstract model entirely in terms of RDF while maintaining the "interface" to constructs defined in the third component of the 2007 model, the Description Set Model.
Relationship of DCAM's Description Set Model to RDF
The centerpiece of DCAM is the Description Set Model, and the relationship of constructs of this model to RDF are described in the 2008 guidelines, Expressing Dublin Core™ metadata using the Resource Description Framework (DC-RDF).
The Description Set Model specifies both a set of syntactic elements (things found in data) and a set of referents in the real world (things to which the syntactic elements may be interpreted to refer). Ignoring the semantic element of the Description Set Model, which has been justifiably criticized as "confusing", it is possible to view the Description Set Model strictly in terms of its syntactic elements. These include grouping constructs (Description Set, Description, Statement, Non-Literal Value Surrogate, and Literal Value Surrogate) and slots for URIs and character strings (Described Resource URI, Property URI, Value URI, Vocabulary Encoding Scheme URI, Syntax Encoding Scheme URI, Value String Language, Plain Value String, and Typed Value String). One might think of these slots as components of the DCAM abstract syntax that can be tested or validated. In the DCMI Abstract Model, these syntactic elements are described using UML, but they are more popularly depicted in the form of a nested metadata template, as in Figure 1 below.
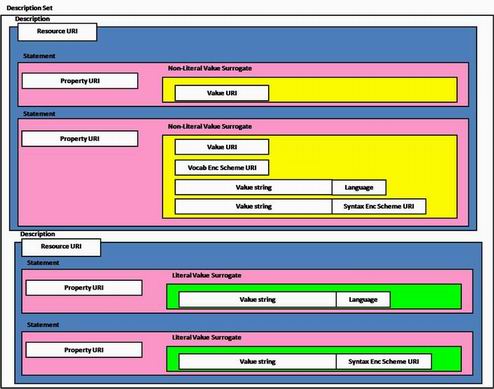
Figure 1: Description Set Model (part of DCMI Abstract Model)
As an illustration of how the syntactic elements of the Description Set Model are used, Figure 2 shows a set of example information values in the placeholders corresponding to those shown in Figure 1.
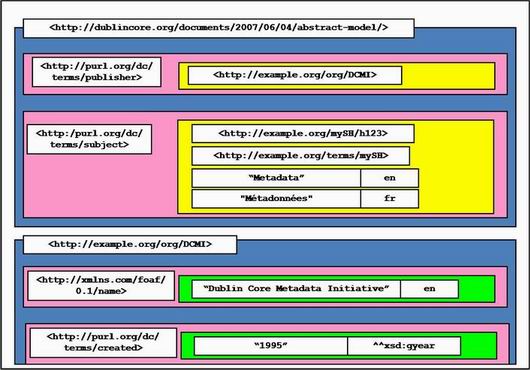
Figure 2: Description Set Model slots with example URIs and character strings
How the elements of the Description Set Model relate to RDF is depicted in Figure 3 and described in more detail in Appendix B below.
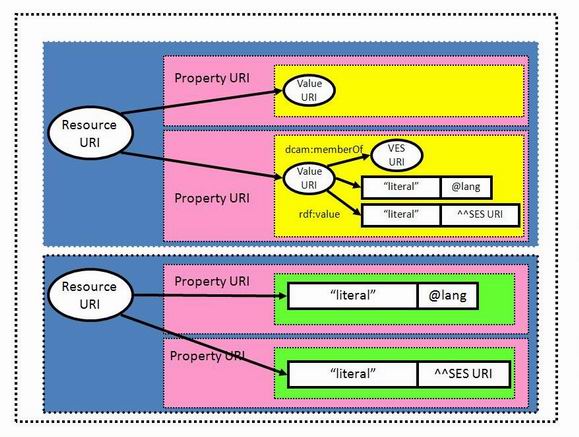
Figure 3: Relationship of Description Set Profile components to RDF graphs
Future development of DCAM
It is difficult to track the use of freely available specifications once they are released on the Web, but as of 2010, DCMI was not aware that any of the DCAM-related specifications, with the possible exception of specific syntax guidelines, had been widely implemented. Rather than building a bridge from more traditional metadata communities to the Semantic Web, the Abstract Model appeared to have fallen between two stools - its use of the "description set" abstraction perplexing to users more accustomed to metadata specifications defined in terms of a concrete syntax, and its added layer of Dublin-Core-specific terminology confusing to users already comfortable with the RDF model. Faced with a lack of uptake of the DCAM-based approach to application profiles, DCMI undertook a critical review of the DCAM specification stack as the basis for a discussion at a joint meeting of the DCMI Architecture Forum and the W3C Library Linked Data Incubator Group in October 2010.